

Prédire les résultats de l’élection présidentielle française de 2022 en analysant les tweets de l’édition 2017 (Lettria) | de Heka.ai | avril 2022

Vous êtes-vous déjà demandé s’il était possible de prédire le résultat de l’élection présidentielle française en analysant Twitter ?
Pour répondre à cette question, j’ai utilisé Lettria pour analyser les tweets liés aux élections présidentielles françaises qui ont eu lieu en avril et mai 2017. L’objectif est de prédire le pourcentage de votes obtenus par les candidats lors de ces élections, puis d’utiliser les méthodes développées pour prédire les résultats des élections de 2022.
En 2017, 11 candidats étaient en lice jusqu’au premier tour, puis seuls deux candidats s’affrontaient pour devenir président. J’ai étudié les tweets écrits 2 jours avant le premier tour et 2 jours avant le second tour pour étudier une quantité de données représentative mais toujours gérable. Le jeu de données que j’ai utilisé se trouve ici : https://www.kaggle.com/datasets/jeanmidev/french-presidential-election.
Il contient environ 8 millions de tweets liés aux élections de 2017. Je n’utilisais que la partie texte des tweets, donc je travaillais avec des données non structurées. Étudier les tweets peut être instructif, mais il faut être conscient qu’ils ne représentent guère la population électorale française car les utilisateurs de Twitter sont plus jeunes et ont tendance à être plus polarisés politiquement, ce qui conduit à une surreprésentation des idées extrêmes sur les réseaux sociaux.
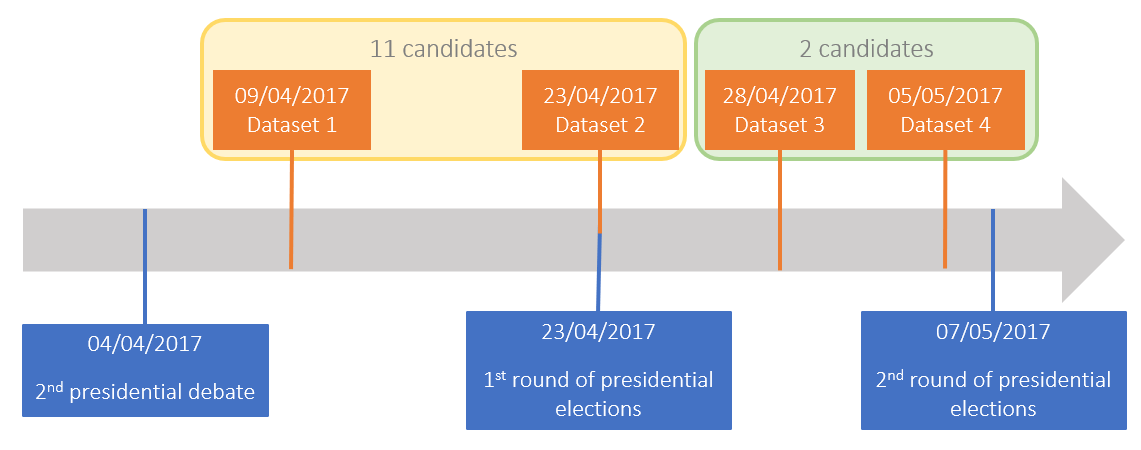
Chronologie des jours analysés à partir du jeu de données
La première approche a été d’analyser le sentiment des tweets et plus particulièrement de chaque phrase composant le tweet. Chaque phrase positive serait alors comptée comme un vote pour le candidat qui y est mentionné. La première étape consiste à diviser chaque tweet en ses phrases correspondantes. Pour ce faire, j’ai utilisé la commande nlp.sentences proposée par Lettria, qui retourne toutes les phrases d’un document. Ensuite, j’ai évalué le sentiment de chaque phrase en utilisant nlp.sentiment_ml qui renvoie une valeur entre -1 et 1 (les valeurs positives indiquent une phrase positive). J’ai décidé de compter chaque phrase positive comme un vote pour un candidat si un seul candidat y est mentionné. Le but ici est d’éviter les situations où deux candidats sont mentionnés, l’un avec un sentiment positif et l’autre avec un sentiment négatif. Un exemple pourrait être : « J’aime beaucoup Candidat_A car leurs idées sont nouvelles et nécessaires pour notre grand pays, ce n’est pas le cas de Candidat_B ». Nous pouvons voir ici que seul Candidat_A est vu positivement dans la phrase. Pourtant, si nous vérifions les candidats mentionnés dans cette phrase, cela compterait comme un vote pour les deux candidats, ce qui n’a pas de sens ici.
J’ai obtenu les résultats suivants :

Pourcentage de condamnations positives par rapport aux résultats réels par candidat (09.04.2017 et 23.04.2017)
Les résultats obtenus sont intéressants, mais on constate que pour deux candidats les prédictions sont assez différentes des résultats (Fillon et Le Pen). Cela peut s’expliquer par le fait que davantage de tweets mentionnant ces deux candidats sont présents dans l’ensemble de données avec lequel nous avons commencé. De plus, cette analyse ne considère que le sentiment de la phrase et non ses émotions ce qui peut nous donner une analyse plus riche de la phrase. Par conséquent, j’ai décidé de prendre également en compte l’émotion des phrases. J’ai utilisé la commande nlp.emotion_ml, qui renvoie la ou les émotions de la phrase. J’ai établi une liste de toutes les émotions négatives pouvant être renvoyées par la commande nlp.emotion_ml (‘colère’, ‘agacement’, ‘confusion’, ‘déception’, ‘désapprobation’, ‘dégoût’, ’embarras’, ‘peur ‘, ‘chagrin’, ‘nervosité’, ‘tristesse’). Si l’une de ces émotions négatives se trouve dans une phrase positive avec un score faible (<0,1) alors cette phrase ne sera pas considérée comme un vote pour le candidat qui y est mentionné. Par exemple, « Fillon n'aime que son argent. [(‘disapproval’, 1)] 0,08" serait supprimé même s'il s'agit d'une phrase positive (valeur de 0,08), car l'émotion associée est négative et la valeur positive de la phrase entière est inférieure à 0,1
J’ai obtenu les résultats suivants avec cette approche :
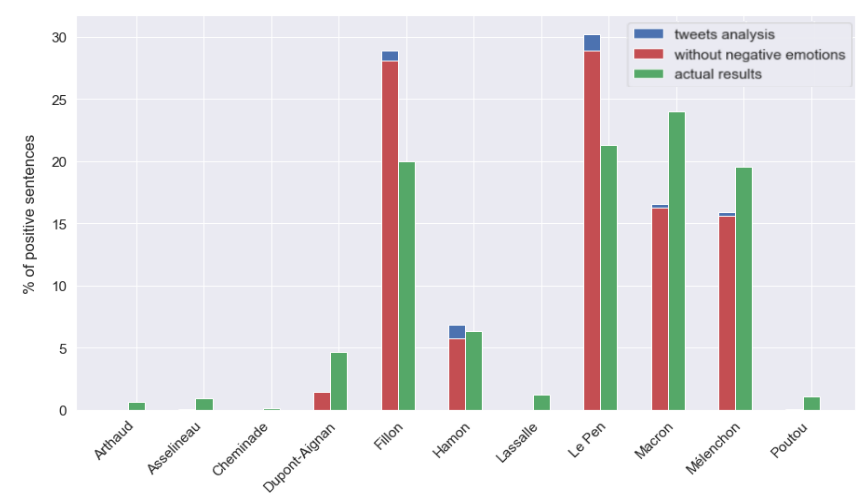
Pourcentage de phrases positives sans émotions négatives par rapport aux résultats réels par candidat (09.04.2017 et 23.04.2017)
Nous pouvons voir que les prédictions sans émotions négatives sont très similaires aux prédictions obtenues précédemment, seules quelques phrases sont retirées des phrases positives avec lesquelles nous étions au départ. Pourtant, on constate que le nombre de phrases supprimées est plus important pour les deux candidats qui avaient un plus grand écart entre les résultats prédits et les résultats réels. Cela pourrait s’expliquer non seulement par le nombre plus élevé de tweets sur ces candidats (donc plus de tweets sont supprimés) mais aussi par le sarcasme. En effet, il peut être compliqué pour le modèle de percevoir le sarcasme et l’analyse de l’émotion peut aider à le repérer.
Par conséquent, les résultats présentés ci-dessus sont intéressants mais pourraient être améliorés, c’est pourquoi j’ai étudié une seconde approche. Avec cette approche, je n’ai pris en considération que les intentions de vote exprimées. Pour ce faire, j’ai utilisé la commande nlp.match_pattern. Cette commande vous permet de trouver des phrases selon un certain modèle ou certaines règles. J’ai utilisé le modèle suivant :
« vote »:[
{“LEMMA”:”voter”},
{“POS”:{“IN”:[“P”]}, « OP »: »? »},
{« POS »:{« IN »:[“NP”]}}
]}
Avec ce motif, la commande match_pattern recherche d’abord tous les lemmes du verbe « voter » (« voter » en français), puis s’il est (ou non) suivi d’une préposition, et enfin d’un nom propre. Avec cette structure, des phrases comme « Je vais voter pour Candidat_A demain » sera trouvé. Après avoir trouvé toutes les phrases correspondant au modèle « vote », le nom propre à la fin de chaque modèle sera vérifié pour s’assurer qu’il correspond à un candidat. Alors cette phrase sera comptée comme un vote pour ce candidat.
J’ai également ajouté une boucle pour analyser le sentiment de la phrase contenant le motif avec nlp.sentiment_ml. En effet, si le sentiment est négatif, la peine ne comptera pas comme un vote pour le candidat. Cela nous permet de supprimer des phrases similaires à cet exemple : « Voter pour Candidat_A ? ! Je ne aurais jamais!! » car cette phrase n’est pas un vote pour le candidat_A mais pourrait être comptée comme un vote pour si seulement en utilisant le modèle « vote ».
J’ai obtenu les résultats suivants :

Pourcentage des intentions de vote exprimées par rapport aux résultats réels par candidat (09.04.2017 et 23.04.2017)
On peut noter que les résultats sont pour la plupart cohérents. Pourtant, pour certains candidats, les prédictions sont assez différentes des résultats obtenus (Hamon et Le Pen). Une explication pourrait être que l’un de ces candidats avait une campagne contenant le modèle « vote ». En effet, lors de sa campagne Hamon utilisait « #JeVotePour » (« #IVoteFor ») pour partager certaines de ses idées. Cela pourrait expliquer pourquoi les intentions de vote prévues sont supérieures aux résultats réels.
Pour le second tour des élections, deux candidats restent : Le Pen et Macron. Pour prédire les résultats, j’ai d’abord utilisé la même analyse de sentiment que nous avons vue précédemment : séparer les tweets en phrases avec nlp.sentences, puis analyser le sentiment de chaque phrase avec nlp.sentiment_ml, et enfin analyser les émotions de chaque phrase avec nlp.emotion_ml et sans compter les phrases avec émotion(s) négative(s) et un sentiment positif faible (<0,1).
J’ai obtenu les résultats suivants :

Pourcentage de phrases positives (sans émotions négatives) par rapport aux résultats réels par candidat (28.04.2017 et 05.05.2017)
La différence entre les résultats prédits et les résultats réels des élections pourrait s’expliquer par la difficulté pour le modèle de reconnaître le sarcasme et donc de compter certains des tweets sarcastiques comme positifs. Une autre explication possible de cette différence pourrait être l’âge des utilisateurs de Twitter. En effet, parmi les électeurs âgés de 18 à 50 ans, plus de 40 % d’entre eux ont voté pour Le Pen, or ce nombre est inférieur à 30 % pour les électeurs de plus de 50 ans. Par conséquent, comme la plupart des jeunes utilisent Twitter, cela pourrait être une raison pour laquelle Le Pen est plus représenté dans ces tweets.
J’ai finalement utilisé une approche de filtrage par motif pour prédire les résultats du second tour des élections avec nlp.match_pattern. J’ai non seulement utilisé le motif « vote » tel que présenté ci-dessus mais aussi un motif « vote_against ». En effet, lors du premier tour des élections puisque plusieurs candidats sont en lice, voter contre quelqu’un ne suffit pas pour savoir pour quel candidat l’auteur du tweet va voter. Au contraire, pour le second tour, voter contre un candidat revient à voter pour l’autre. J’ai donc utilisé le modèle suivant :
« vote_against »:[
{“LEMMA”:”voter”},
{“TEXT”:”contre”},
{“POS”:{“IN”:[“NP”]}}
],
Cette fois, le motif est composé du lemme du verbe « voter », suivi du mot « contre » (« contre » en français) et enfin d’un nom propre. Chaque phrase contenant le motif « vote_against » compte comme un vote pour le candidat qui n’est pas mentionné à la fin du motif. La combinaison de ces deux modèles nous permet d’obtenir les résultats suivants :

Pourcentage d’intentions de vote exprimées par rapport aux résultats réels par candidat pour le second tour (28.04.2017 et 05.05.2017)
Comme nous pouvons le voir sur le graphique à barres, l’inclusion du modèle vote_against nous aide à obtenir des résultats légèrement plus précis. Les prévisions globales sont proches des résultats réels obtenus lors des élections tout en étant un peu trop élevées pour Macron et trop basses pour Le Pen. On pourrait imaginer que les utilisateurs de Twitter ont tendance à soutenir Macron plus (et Le Pen moins) que l’ensemble des électeurs français ou que les utilisateurs de Twitter expriment plus facilement leurs intentions de vote lorsqu’ils ont l’intention de voter pour Macron.
La dernière étape de ce projet consistait à appliquer les méthodes développées sur les élections présidentielles de 2017, aux élections présidentielles de 2022. Pour ce faire, j’ai supprimé les tweets liés aux deux candidats (et à leurs partis) deux jours avant le second tour de la élections : les 12.04.2022 et 19.04.2022.
Après avoir prétraité les données et les avoir ajoutées à l’API de Lettria, j’ai pu utiliser les approches présentées ci-dessus pour calculer les prévisions pour le second tour des élections.
En utilisant l’approche d’analyse des sentiments (sans émotions négatives), j’ai obtenu les résultats suivants : (plus précisément 37,1 % de phrases positives pour Le Pen et 62,9 % pour Macron)

Pourcentage de phrases positives (sans émotions négatives) par rapport aux résultats de la dernière élection par candidat (12.04.2022 et 19.04.2022)
J’ai ensuite utilisé l’approche de correspondance de modèles avec les deux modèles (« vote » et « vote_against »). J’ai obtenu les résultats suivants : (plus précisément 36,7% d’intentions de vote pour Le Pen et 63,3% pour Macron)

Pourcentage d’intentions de vote exprimées par rapport aux résultats des dernières élections par candidat (12.04.2022 et 19.04.2022)
Contrairement aux résultats des élections précédentes, les deux approches nous donnent des résultats très proches. En effet, les deux méthodes après les avoir utilisées sur les tweets du 12.04.2022 et du 19.04.2022 prévoyaient environ 37% des voix pour Marine Le Pen et 63% des voix pour Emmanuel Macron.
Il est important de rappeler que ces résultats ne sont obtenus qu’en étudiant les tweets sur deux jours différents et ne sauraient être représentatifs de l’ensemble de la population votante. De plus, si l’on compare les résultats obtenus par la méthode du pattern matching, les prévisions pour les dernières élections étaient trop hautes pour Emmanuel Macron et trop basses pour Marine Le Pen. On pourrait imaginer que les utilisateurs de Twitter pourraient avoir les mêmes tendances pour ces élections. Ainsi, il est possible d’imaginer que les résultats réels seront un peu inférieurs pour Macron et un peu supérieurs pour Le Pen. Réponse le 24.04.2022 !
Nous avons vu deux approches principales pour tenter de prédire le résultat des élections présidentielles françaises. Évaluez le sentiment véhiculé par les tweets ou considérez les intentions de vote exprimées avec le pattern matching. Ces méthodes nous donnent des résultats perspicaces sur les candidats et leurs résultats.
Les prédictions que nous avons obtenues sont à prendre avec des pincettes. En effet, l’analyse de Twitter ne montre pas fidèlement ce que les électeurs français entendaient faire car il n’est pas représentatif de la population votante. Pourtant, pour essayer d’améliorer les résultats prévus, plusieurs idées pourraient être développées. L’un d’eux consiste à analyser le nombre de likes des tweets, en nous informant de l’opinion des autres utilisateurs à ce sujet. Une autre possibilité serait de vérifier le nom des utilisateurs, pour s’assurer qu’on ne compte pas deux fois le même utilisateur sur deux jours différents par exemple. Enfin, il serait bien sûr intéressant d’analyser les données de toute la période pré-électorale et de ne pas limiter cette étude à quatre jours seulement.
Au lieu de nous éclairer sur les intentions de vote des Français pour cette élection, peut-être cette étude pourra-t-elle nous montrer dans quelle mesure la société française est effectivement représentée par twitter et donc quelles sont les précautions à prendre lorsque des études similaires sont menées.