
Ensemble de données comportementales du monde réel provenant de deux essais cliniques randomisés entièrement à distance sur smartphone pour la dépression
Éclairer les études V1 et V2
Les deux essais cliniques randomisés, l’étude Brighten (Bridging Research Innovations for Greater Health in Technology, Emotion, and Neuroscience) V129(désormais V1) et Brighten V2sept(ci-après V2), ont été utilisés pour étudier : 1) la faisabilité de mener des essais cliniques décentralisés entièrement à distance7,292) l’efficacité relative des applications de santé numériques pour améliorer l’humeur303) utilité des données comportementales du monde réel collectées passivement à partir de smartphones pour prédire les changements d’humeur au fil du temps au niveau de la population et de l’individu31 et 4) les facteurs ayant une incidence sur le recrutement et la rétention des participants dans la recherche décentralisée en santé32. Les deux études ont déployé trois interventions à distance basées sur des applications et ont recueilli des données du monde réel (actives : enquêtes à distance et passives : utilisation du smartphone) liées à la dépression partagées et décrites ici.
Dans l’ensemble, 7 850 participants de partout aux États-Unis ont été sélectionnés, avec 2 193 participants répondant aux critères d’éligibilité et consentant à s’inscrire aux deux études (Figs. 1, 2 ; Tableau 1). L’analyse des données d’engagement au niveau individuel a montré une variation significative dans la rétention des participants liée à des facteurs démographiques et socio-économiques décrits plus en détail dans les deux études7,32. Sévérité moyenne de la dépression des participants à l’étude (évaluée à l’aide de l’enquête PHQ-933) lors de l’intégration indiquaient des symptômes de dépression modérée (V1 : 14 ± 5,1, V2 : 14,3 ± 5,4). Une proportion notable de la cohorte a indiqué des idées suicidaires (réponse non nulle à 9e élément de PHQ-9) à l’intégration (V1 : 29,4 %, V2 : 35,6 %).
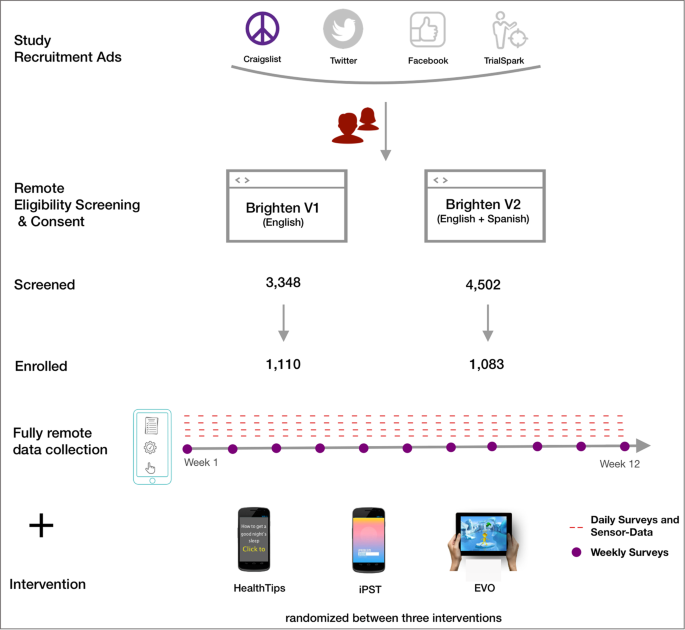
Schéma général montrant le processus d’intégration des participants depuis le recrutement en ligne et la collecte de données prospectives à l’aide de smartphones jusqu’à l’attribution aléatoire à l’une des interventions de l’étude.
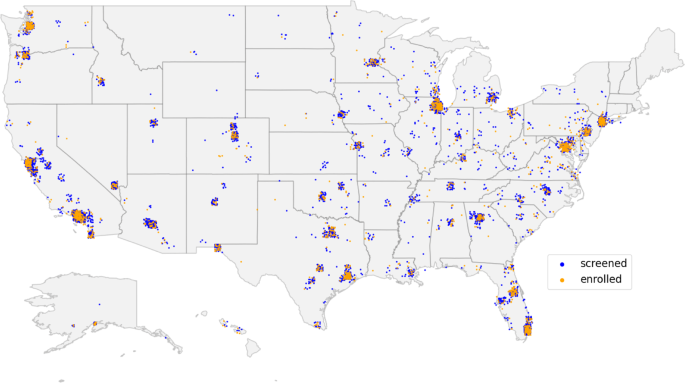
Carte des États-Unis montrant l’emplacement des participants* qui ont été dépistés (bleu) et inscrits (jaune) dans les deux études Brighten. *Basé sur les participants qui ont partagé au moins les trois premiers chiffres de leur code postal.
Il y avait des différences significatives de race/ethnicité entre les deux cohortes d’étude (hispanique/latino V1 : 13 %, V2 : 38 %), principalement en raison de différences sous-jacentes dans les approches de recrutement entre les études. Utiliser des approches de recrutement ciblées (décrites plus en détail icisept), nous avons enrichi la cohorte de l’étude V2 pour les Hispaniques/Latinos afin d’aider à étudier la faisabilité de l’utilisation d’outils numériques de santé mentale dans cette population cible. Voir le tableau 2 pour plus de détails et un résumé descriptif de la cohorte globale stratifiée par les études V1 et V2.
Étudier le design
Les études Brighten (V1 et V2) visaient à évaluer la faisabilité de mener des essais cliniques randomisés entièrement à distance sur smartphone pour évaluer et proposer des interventions numériques aux personnes souffrant de dépression. Alors que les deux essais étaient ouverts à toute personne répondant aux critères d’éligibilité, Brighten V2 s’est concentré sur l’augmentation de la participation des populations hispaniques/latinos. La surveillance éthique et l’approbation des deux essais (V1:NCT00540865, V2:NCT01808976) ont été accordées par l’Institutional Review Board de l’Université de Californie à San Francisco. Les participants aux deux études ont été randomisés dans l’une des trois applications d’intervention et observés de manière prospective pendant 12 semaines. Les trois applications d’intervention étaient : 1.) iPST – une application basée sur la thérapie de résolution de problèmes34,35un traitement fondé sur des données probantes pour la dépression, 2.) Project Evo – un jeu vidéo thérapeutique destiné à améliorer les compétences cognitives associées à la dépression36et 3.) Health Tips – une application qui fournit des informations sur les stratégies pour améliorer l’humeur.
Recrutement et intégration des participants
Les participants devaient parler anglais ou espagnol (en V2), être âgés d’au moins 18 ans et posséder soit un iPhone avec des capacités Wi-Fi ou 3 G/4 G/LTE, soit un téléphone Android avec un Apple iPad version 2.0 ou un appareil plus récent. Dans les deux études, les participants devaient présenter des symptômes de dépression cliniquement significatifs, comme indiqué par un score de 5 ou plus au PHQ-9 ou un score de 2 ou plus au PHQ item 10.
Les participants ont été recrutés en utilisant une combinaison de trois approches différentes – méthodes traditionnelles (annonces placées dans les médias locaux), publicité basée sur les réseaux sociaux (annonces sur Facebook et Craigslist) et campagnes de recrutement ciblées en ligne (en partenariat avec Trialspark.com pour l’étude V2 ). Le processus d’intégration impliquait de se renseigner sur l’étude via le site Web de l’étude. Une vidéo mettant en évidence les objectifs et les procédures de l’étude de recherche ainsi que les risques et les avantages de la participation a également été mise à disposition.
Après avoir visionné la vidéo et lu le consentement à l’étude en ligne, les participants devaient répondre correctement à trois questions pour confirmer leur compréhension du fait que la participation était volontaire, ne se substituait pas au traitement, et qu’ils étaient randomisés dans des conditions de traitement. Chaque question devait recevoir une réponse correcte avant qu’un participant puisse consentir à participer, après quoi il pouvait passer à l’évaluation de base et à la randomisation. Le consentement des participants à participer à l’étude a été demandé avant que leur admissibilité à l’inscription puisse être établie. Cela a été fait pour évaluer leur état de dépression de base (via l’enquête PHQ-9), qui était nécessaire pour répondre aux critères d’éligibilité de l’étude et ne pouvait pas être recueilli sans le consentement du participant. Dans le formulaire de consentement signé par les participants, il y avait une clause décrivant que d’autres organisations et chercheurs peuvent utiliser ces données pour la recherche et l’assurance qualité. Cela fait suite à la politique de partage des données de l’Institut national de la santé mentale (NIMH) (NOT-MH-19-033), conçue pour partager les données à la fin de la période d’attribution ou lors de la publication des résultats de la recherche.
Une fois confirmés, les participants ont reçu un lien pour télécharger l’application d’intervention de l’étude qui leur avait été assignée au hasard. L’étude V2 a traduit le matériel de recrutement en espagnol pour les hispanophones. Les participants ont été rémunérés pour leur temps dans les deux études. Chaque participant a reçu jusqu’à 75 USD de chèques-cadeaux pour avoir effectué toutes les évaluations au cours de la période d’étude de 12 semaines : 15 USD après avoir terminé l’évaluation initiale de référence et 20 USD pour chaque évaluation ultérieure à 4, 8 et 12 semaines.
La collecte de données comprenait des données autodéclarées par les participants à l’aide d’une combinaison d’instruments d’enquête validés et de courtes évaluations écologiques momentanées. Nous avons également collecté des données de capteurs passifs à partir de smartphones liés aux activités quotidiennes des participants, comme décrit ci-dessous.
Évaluation de base
Tous les participants consentants aux études V1 et V2 ont fourni les mêmes informations de base. L’enquête démographique portait sur l’âge, la race/ethnicité, le statut matrimonial et professionnel, le revenu et l’éducation. Pour évaluer l’état de santé mentale des participants au départ, nous avons utilisé les échelles suivantes : Le questionnaire sur la santé du patient (PHQ-9)33 pour mesurer les symptômes de la dépression, échelle d’incapacité de Sheehan (SDS)37 pour évaluer la déficience fonctionnelle et le trouble anxieux généralisé (GAD-7) pour l’anxiété. Le système d’inscription signalait tout participant indiquant des idées suicidaires (réponse non nulle au 9e item de l’enquête PHQ-9). Il a été suggéré à ces participants que cette étude n’était peut-être pas la meilleure solution pour eux et qu’ils devraient envisager de contacter leur fournisseur de soins de santé. Nous avons également fourni des liens vers des ressources en ligne, y compris une ligne d’assistance téléphonique d’aide au suicide 24 heures sur 24, pour recevoir une aide immédiate.
Tous les participants ont été évalués pour des antécédents de manie, de psychose et de consommation d’alcool à l’aide d’un instrument de dépistage de la manie et de la psychose en quatre points38 et le test de dépistage de l’alcool en quatre points de l’Institut national sur l’abus d’alcool et l’alcoolisme (NIAAA). Nous avons également interrogé les participants à l’étude sur la possession d’appareils intelligents, l’utilisation d’applications de santé et les services de santé mentale, y compris l’utilisation de médicaments et la psychothérapie. On a demandé aux participants d’évaluer leur état de santé sur une échelle allant d’excellent à mauvais. Toutes les évaluations de base ont été recueillies auprès des participants éligibles avant que les interventions ne soient fournies, et toutes les questions étaient facultatives pour les participants. Pour de plus amples descriptions des évaluations cliniques et des autres enquêtes administrées dans les études V1 et V2, veuillez visiter le portail de données de l’étude Brighten (www.synapse.org/brighten).
Collecte de données longitudinales
Les participants ont répondu à des questions quotidiennes et hebdomadaires à l’aide de l’application d’étude et d’une collecte de données passive continue. L’application de l’étude n’a pas collecté d’informations privées telles que le contenu des SMS, des e-mails ou des appels vocaux.
Tâches actives
Les participants ont effectué des évaluations des résultats primaires à l’aide des enquêtes PHQ-9 et SDS une fois par semaine pendant les quatre premières semaines, puis toutes les deux semaines pendant toute la durée de l’étude (12 semaines). Pour évaluer l’humeur et l’anhédonie des participants (symptômes principaux de la dépression), nous avons utilisé l’enquête PHQ-2 administrée quotidiennement le matin. Les participants ont également rempli d’autres mesures secondaires (décrites ci-dessous) à des intervalles quotidiens, hebdomadaires ou bihebdomadaires. Celles-ci comprenaient une évaluation du sommeil avec trois questions – le temps nécessaire pour s’endormir, la durée du sommeil et le temps d’éveil pendant la nuit. Chaque question utilisait une échelle de temps Likert à choix multiples (par exemple, 0 à 15 minutes, 16 à 30 minutes, 31 à 60 minutes, etc.) pour répondre à ces questions sur le sommeil. Les participants ont été automatiquement avertis toutes les 8 heures, pendant 24 heures, s’ils n’avaient pas répondu à une enquête dans les 8 heures suivant sa livraison initiale. Une évaluation était considérée comme manquante si elle n’était pas terminée dans ce délai de 24 heures.
Collecte de données passive
Pour l’étude V1, nous avons déployé une application en collaboration avec Ginger.io qui collectait des données passives. L’application a automatiquement lancé les processus de collecte de données en arrière-plan une fois que l’utilisateur s’est connecté. Après la connexion initiale, le processus a été automatiquement lancé chaque fois qu’il n’était pas déjà en cours d’exécution (au redémarrage du téléphone ou à d’autres événements mettant fin au processus). Les données collectées via l’appareil incluent les métadonnées de communication (par exemple, l’heure de l’appel/SMS, la durée de l’appel, la longueur du SMS) et les données mobiles telles que le type d’activité et la distance parcourue. L’application de l’étude n’a pas collecté de données de communication personnelles et identifiables telles que le texte réel des SMS ou les numéros de téléphone des appels entrants et sortants.
Dans l’étude V2, nous avons développé une application interne nommée Enquête pour aider à collecter des données comportementales plus fines. Les flux de données passifs comprenaient un résumé descriptif quotidien des communications téléphoniques (par exemple, le nombre d’appels et de SMS) et des localisations GPS intrajournalières. Si des services de localisation (GPS) étaient disponibles, l’application de l’étude enregistrait la latitude et la longitude toutes les dix minutes ou un mouvement à plus de 100 mètres du point précédemment enregistré. Bien que les données GPS brutes des participants ne puissent pas être largement partagées en raison de la confidentialité des données, nous partageons des résumés granulaires intrajournaliers des caractéristiques dérivées des données GPS brutes. Pour caractériser les données GPS brutes, nous avons développé un pipeline open-source, gSCAP-Geospatial Context Analysis Pipeline (https://github.com/aid4mh/gSCAP). En bref, le pipeline gSCAP utilise des données GPS brutes et sensibles au niveau individuel pour générer une sémantique géospatiale au niveau individuel qui n’est pas identifiable de la même manière que les coordonnées GPS. Quelques exemples de ces caractéristiques contextuelles incluent la mobilité quotidienne globale (temps et distance de marche, vélo, etc.), la météo quotidienne moyenne (température, rosée, nuage) à l’emplacement du participant et le type de lieux visités en une journée (café, parc , centre commercial, etc.). Cependant, le pipeline n’extrait pas et ne stocke pas la localisation des différents lieux visités).
De plus amples détails sur la conception de l’étude, le recrutement des participants, l’intégration et la collecte de données sont disponibles dans Brighten V129 et V2sept papiers, respectivement.
Stockage et sécurité des données
Les données brutes initiales de chaque étude ont été collectées et stockées sur des serveurs conformes à la loi HIPAA situés dans le département de neurologie de l’Université de Californie à San Francisco. Les serveurs de l’étude ont été configurés selon les normes et les politiques des normes de sécurité minimales de l’UCSF pour les ressources d’information électroniques.