

Une nouvelle technologie d’intelligence artificielle protège la confidentialité dans les établissements de santé Nouvelles impériales


Des chercheurs de TUM et de l’Impériale ont développé une technologie qui protège les données personnelles des patients tout en formant des algorithmes de soins de santé.
La technologie a maintenant été utilisée pour la première fois dans un algorithme qui identifie la pneumonie dans les images radiographiques d’enfants. Les chercheurs ont constaté que leurs nouvelles techniques de protection de la vie privée montraient une précision comparable ou meilleure dans le diagnostic de diverses pneumonies chez les enfants que les algorithmes existants.
Garantir la confidentialité et la sécurité des données de santé est essentiel pour le développement et le déploiement de modèles d’apprentissage automatique à grande échelle. Professeur Daniel Rueckert Département d’informatique
Les algorithmes artificiellement intelligents (IA) peuvent aider les cliniciens à diagnostiquer des maladies comme les cancers et la septicémie. L’efficacité de ces algorithmes dépend de la quantité et de la qualité des données médicales utilisées pour les former, et les données des patients sont souvent partagées entre les cliniques pour maximiser le pool de données.
Pour protéger ces données, le matériel subit généralement une anonymisation et une pseudonymisation, mais les chercheurs affirment que ces garanties se sont souvent révélées insuffisantes en termes de protection des données de santé des patients.
Pour résoudre ce problème, une équipe interdisciplinaire de l’Université technique de Munich (TUM), de l’Imperial College de Londres et de l’organisation à but non lucratif OpenMined a développé une combinaison unique de processus de diagnostic basés sur l’IA pour les données d’images radiologiques qui protège la confidentialité des données.
Dans leur article, publié dans Intelligence artificielle de la nature, l’équipe présente une application réussie: un algorithme d’apprentissage en profondeur qui permet de classer les conditions de pneumonie sur les radiographies d’enfants.
Le co-auteur, le professeur Daniel Rueckert, du Département d’informatique de l’Impériale et TUM, a déclaré: «Garantir la confidentialité et la sécurité des données de santé est essentiel pour le développement et le déploiement de modèles d’apprentissage automatique à grande échelle.
La protection de la vie privée
Pour protéger les données des patients, elles ne doivent jamais quitter la clinique où elles sont collectées. Georgios Kassis Département d’informatique
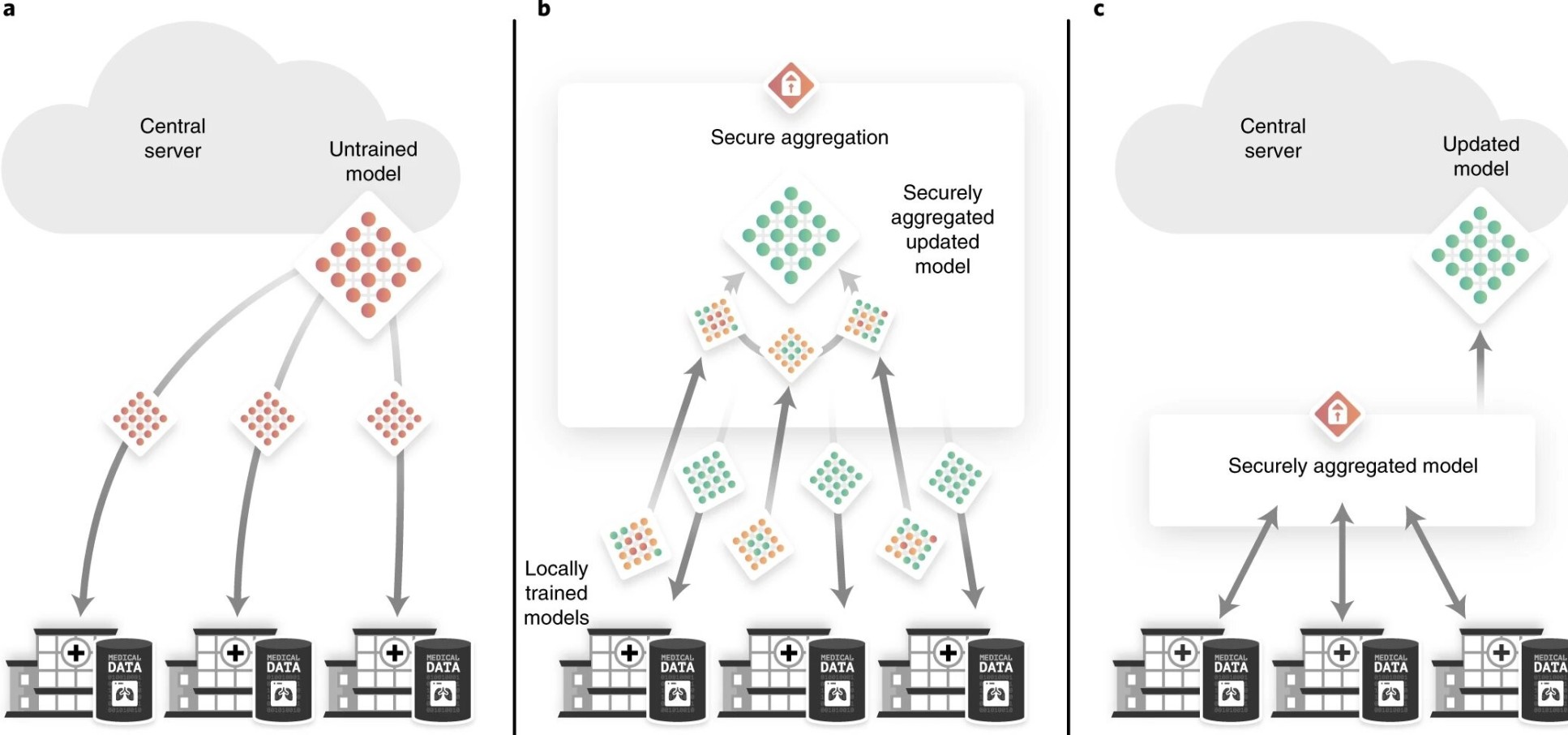
Une façon de protéger les dossiers des patients est de les conserver sur le site de collecte plutôt que de les partager avec d’autres cliniques. Actuellement, les cliniques partagent les données des patients en envoyant des copies de bases de données aux cliniques où les algorithmes sont formés.
Dans cette étude, les chercheurs ont utilisé l’apprentissage fédéré, dans lequel l’algorithme d’apprentissage en profondeur est partagé au lieu des données elles-mêmes. Les modèles ont été formés dans les différents hôpitaux en utilisant les données locales puis renvoyés aux auteurs – ainsi, les propriétaires de données n’ont pas eu à partager leurs données et ont conservé un contrôle complet.
Le premier auteur Georgios Kassis de la TUM et du département informatique de l’Imperial a déclaré: «Pour protéger les données des patients, elles ne doivent jamais quitter la clinique où elles sont collectées.»
Pour éviter l’identification des institutions où l’algorithme a été formé, l’équipe a appliqué une autre technique: l’agrégation sécurisée. Ils ont combiné les algorithmes sous forme cryptée et ne les ont décryptés qu’après avoir été formés avec les données de toutes les institutions participantes.
Nous avons formé avec succès des modèles qui fournissent des résultats précis tout en répondant à des normes élevées de protection des données et de confidentialité. Professeur Daniel Rueckert Département d’informatique
Pour éviter que les données individuelles des patients ne soient filtrées des enregistrements de données, les chercheurs ont utilisé une troisième technique lors de la formation de l’algorithme afin que les corrélations statistiques puissent être extraites des enregistrements de données, mais pas les contributions des personnes individuelles.
Le professeur Rueckert a déclaré: «Nos méthodes ont été appliquées dans d’autres études, mais nous n’avons pas encore vu d’études à grande échelle utilisant des données cliniques réelles. Grâce au développement ciblé de technologies et à la coopération entre spécialistes en informatique et en radiologie, nous avons formé avec succès des modèles qui fournissent des résultats précis tout en répondant à des normes élevées de protection des données et de confidentialité.
Ouvrir la voie à la médecine numérique
La combinaison des derniers processus de protection des données facilitera également la coopération entre les institutions, comme l’équipe l’a montré dans un précédent article publié en 2020. Leur méthode d’IA préservant la vie privée pourrait surmonter les obstacles éthiques, juridiques et politiques – ouvrant ainsi la voie à une utilisation généralisée de L’IA dans les soins de santé, qui pourrait être extrêmement importante pour la recherche sur les maladies rares.
Les scientifiques sont convaincus qu’en préservant la vie privée des patients, leur technologie peut apporter une contribution importante à l’avancement de la médecine numérique. Georgios a ajouté: «Pour former de bons algorithmes d’IA, nous avons besoin de bonnes données, et nous ne pouvons obtenir ces données qu’en protégeant correctement la vie privée des patients. Nos résultats montrent qu’avec la protection des données, nous pouvons faire beaucoup plus pour l’avancement des connaissances que beaucoup de gens ne le pensent. »
Les travaux ont été financés par l’Université technique de Munich, la Fondation allemande pour la recherche, le Consortium allemand contre le cancer, la Fondation TUM, UK Research and Innovation et l’Académie mixte Imperial-TUM d’études doctorales.
Kaissis et Rueckert ont été en partie soutenus par le projet Innovate UK AI Center de 26 millions de livres sterling.
« Confidentialité de bout en bout préservant l’apprentissage en profondeur sur l’imagerie médicale multi-institutionnelle » par Georgios Kaissis et coll., publié le 24 mai 2021 dans Intelligence artificielle de la nature.
Cette histoire est adaptée d’un communiqué de presse de TUM.
Voir le communiqué de presse de cet article