

Des robots qui ressentent la douleur et une IA qui prédit les mouvements des footballeurs – TechCrunch
La recherche dans le domaine de l’apprentissage automatique et de l’IA, désormais une technologie clé dans pratiquement toutes les industries et entreprises, est beaucoup trop volumineuse pour que quiconque puisse tout lire. Cette colonne, Perceptron (anciennement Deep Science), vise à rassembler certaines des découvertes et des articles récents les plus pertinents – en particulier, mais sans s’y limiter, l’intelligence artificielle – et à expliquer pourquoi ils sont importants.
Cette semaine dans AI, une équipe d’ingénieurs de l’Université de Glasgow a développé une « peau artificielle » qui peut apprendre à ressentir et à réagir à une douleur simulée. Ailleurs, des chercheurs de DeepMind ont développé un système d’apprentissage automatique qui prédit où les joueurs de football courront sur un terrain, tandis que des groupes de l’Université chinoise de Hong Kong (CUHK) et de l’Université Tsinghua ont créé des algorithmes capables de générer des photos réalistes – et même des vidéos – d’êtres humains. des modèles.
Selon un communiqué de presse, la peau artificielle de l’équipe de Glasgow a tiré parti d’un nouveau type de système de traitement basé sur des «transistors synaptiques» conçus pour imiter les voies neuronales du cerveau. Les transistors, fabriqués à partir de nanofils d’oxyde de zinc imprimés sur la surface d’un plastique souple, sont connectés à un capteur cutané qui enregistre les changements de résistance électrique.

Crédits image : Université de Glasgow
Bien que la peau artificielle ait déjà été tentée auparavant, l’équipe affirme que leur conception différait en ce qu’elle utilisait un circuit intégré au système pour agir comme une « synapse artificielle » – réduisant l’entrée à un pic de tension. Cela a accéléré le traitement et a permis à l’équipe «d’apprendre» à la peau comment réagir à une douleur simulée en fixant un seuil de tension d’entrée dont la fréquence variait en fonction du niveau de pression appliqué sur la peau.
L’équipe voit la peau utilisée en robotique, où elle pourrait, par exemple, empêcher un bras robotique d’entrer en contact avec des températures dangereusement élevées.
Lié de manière tangentielle à la robotique, DeepMind prétend avoir développé un modèle d’IA, Graph Imputer, qui peut anticiper où les joueurs de football se déplaceront en utilisant des enregistrements de caméra d’un seul sous-ensemble de joueurs. Plus impressionnant encore, le système peut faire des prédictions sur les joueurs au-delà de la vue de la caméra, ce qui lui permet de suivre assez précisément la position de la plupart – sinon de tous – des joueurs sur le terrain.
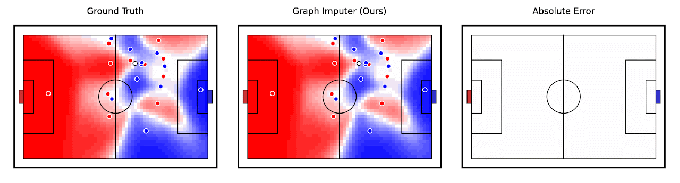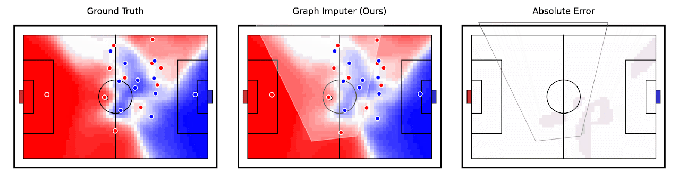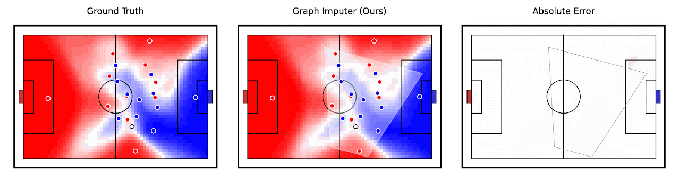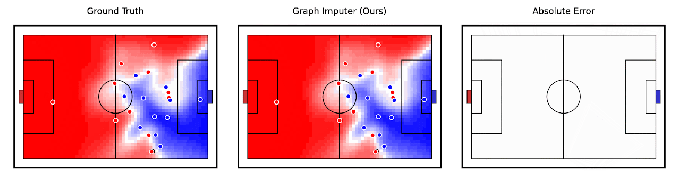
Crédits image : DeepMind
Graph Imputer n’est pas parfait. Mais les chercheurs de DeepMind disent qu’il pourrait être utilisé pour des applications telles que la modélisation du contrôle du terrain ou la probabilité qu’un joueur puisse contrôler le ballon en supposant qu’il se trouve à un endroit donné. (Plusieurs équipes de Premier League de premier plan utilisent des modèles de contrôle du terrain pendant les matchs, ainsi que dans l’analyse d’avant-match et d’après-match.) Au-delà du football et d’autres analyses sportives, DeepMind s’attend à ce que les techniques derrière Graph Imputer soient applicables à des domaines tels que la modélisation des piétons sur modélisation des routes et des foules dans les stades.
Alors que la peau artificielle et les systèmes de prédiction de mouvement sont impressionnants, il est certain que les systèmes de génération de photos et de vidéos progressent à un rythme rapide. Évidemment, il y a des travaux de haut niveau comme Dall-E 2 d’OpenAI et Imagen de Google. Mais jetez un coup d’œil à Text2Human, développé par le laboratoire multimédia de CUHK, qui peut traduire une légende comme « la dame porte un t-shirt à manches courtes avec un motif de couleur pure, et une jupe courte et en jean » en une image d’une personne qui ne n’existe pas réellement.
En partenariat avec l’Académie d’intelligence artificielle de Pékin, l’Université Tsinghua a créé un modèle encore plus ambitieux appelé CogVideo qui peut générer des clips vidéo à partir de texte (par exemple, « un homme en ski », « un lion boit de l’eau »). Les clips regorgent d’artefacts et d’autres bizarreries visuelles, mais étant donné qu’il s’agit de scènes complètement fictives, il est difficile de critiquer aussi durement.
L’apprentissage automatique est souvent utilisé dans la découverte de médicaments, où la variété presque infinie de molécules qui apparaissent dans la littérature et la théorie doit être triée et caractérisée afin de trouver des effets potentiellement bénéfiques. Mais le volume de données est si important et le coût des faux positifs potentiellement si élevé (c’est long et coûteux de rechercher des pistes) que même une précision de 99 % n’est pas suffisante. C’est particulièrement le cas avec les données moléculaires non marquées, de loin la majeure partie de ce qui existe (par rapport aux molécules qui ont été étudiées manuellement au fil des ans).
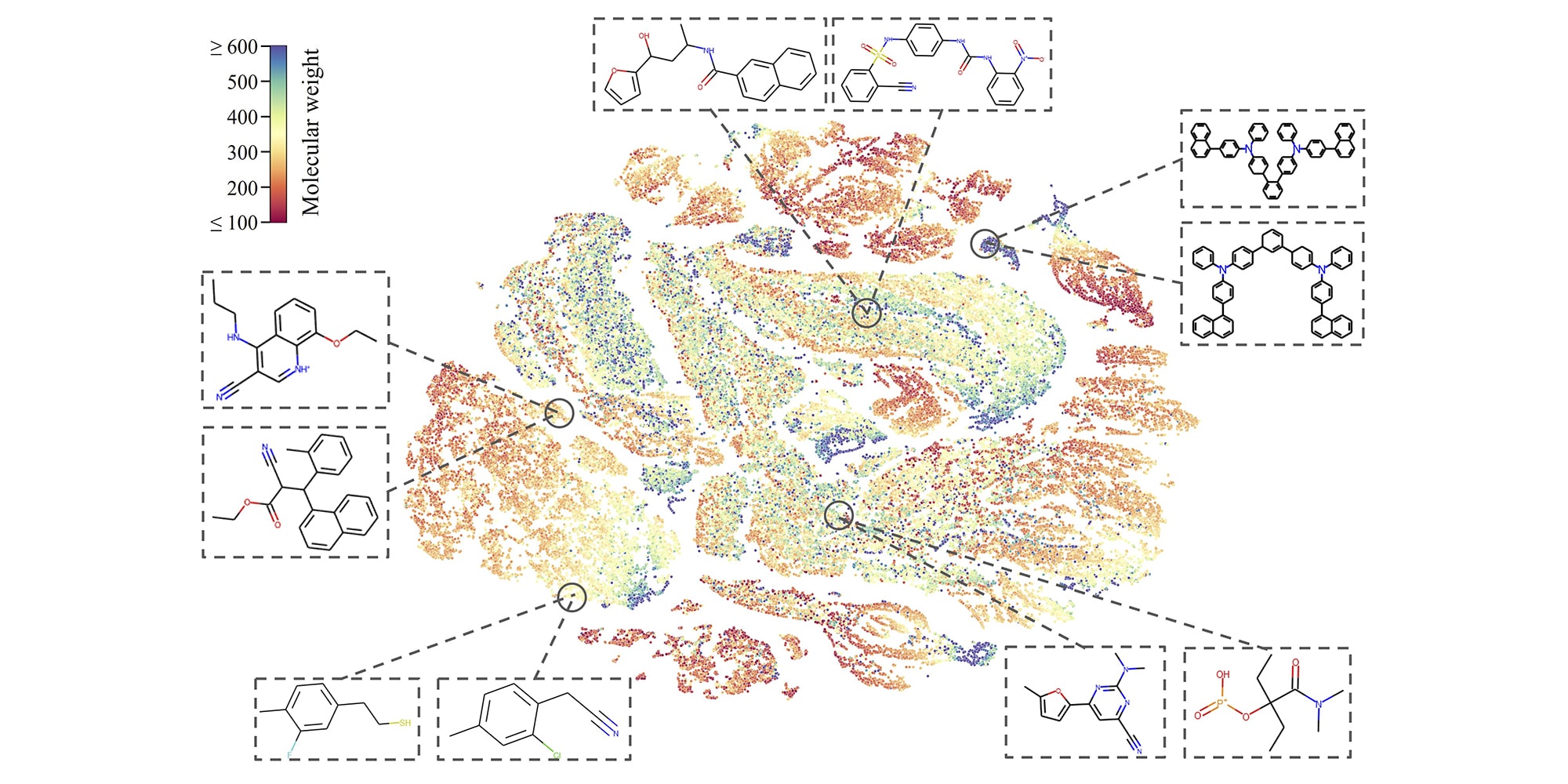
Crédits image : CMU
Les chercheurs du CMU ont travaillé à la création d’un modèle permettant de trier des milliards de molécules non caractérisées en l’entraînant à leur donner un sens sans aucune information supplémentaire. Pour ce faire, il apporte de légères modifications à la structure de la molécule (virtuelle), comme cacher un atome ou supprimer une liaison, et observer comment la molécule résultante change. Cela lui permet d’apprendre les propriétés intrinsèques de la formation et du comportement de ces molécules – et l’a conduit à surpasser les autres modèles d’IA dans l’identification des produits chimiques toxiques dans une base de données de tests.
Les signatures moléculaires sont également essentielles pour diagnostiquer la maladie – deux patients peuvent présenter des symptômes similaires, mais une analyse minutieuse de leurs résultats de laboratoire montre qu’ils ont des conditions très différentes. Bien sûr, c’est une pratique médicale standard, mais à mesure que les données de plusieurs tests et analyses s’accumulent, il devient difficile de suivre toutes les corrélations. L’Université technique de Munich travaille sur une sorte de méta-algorithme clinique qui intègre plusieurs sources de données (y compris d’autres algorithmes) pour différencier certaines maladies du foie avec des présentations similaires. Bien que de tels modèles ne remplacent pas les médecins, ils continueront à aider à gérer les volumes croissants de données que même les spécialistes n’ont peut-être pas le temps ou l’expertise pour interpréter.
[affimax]